

Simplifying Container Configuration in Kubernetes: Adding Persistent Volume to Your Deployment


Introduction:
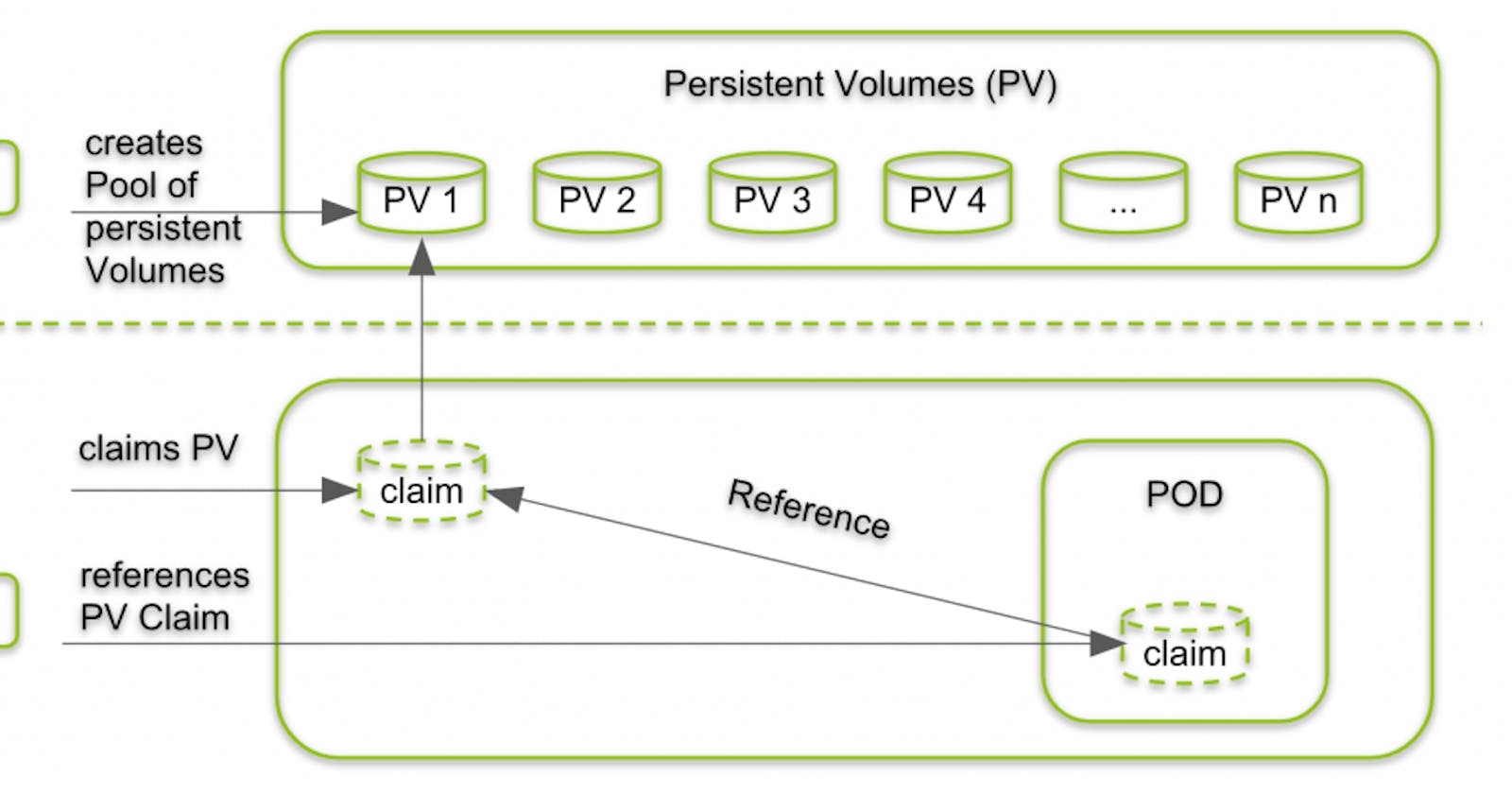
In today's blog post, we will explore how to enhance the functionality and data persistence of your Kubernetes deployment by incorporating a Persistent Volume. By leveraging this powerful feature, you can ensure that your application's data remains intact even if the Pod restarts or migrates. We will walk through the process step-by-step, including creating the Persistent Volume (PV) and Persistent Volume Claim (PVC) YAML files, updating the deployment configuration, and verifying the successful integration. Let's dive in!
Data persistence is crucial in containerized environments for several reasons:
Preserving Data Integrity: Applications often generate and rely on critical data that needs to be retained even when containers are ephemeral and subject to frequent restarts, scaling, or updates. Data persistence ensures that important information remains intact and accessible throughout the container lifecycle.
Stateful Applications: Many applications have a stateful nature and require persistent storage to maintain their operational state. This includes databases, file systems, caching systems, and other components that store critical information. Without data persistence, these applications would lose their state, leading to data corruption and functional disruptions.
Seamless Scalability: Containers offer excellent scalability, allowing applications to be dynamically replicated and distributed across multiple nodes. With data persistence, scaling becomes more seamless, as the underlying data can be shared and accessed consistently across different instances of the application.
Disaster Recovery and Backup: Data persistence enables organizations to implement effective disaster recovery strategies. By persistently storing data, organizations can easily recover and restore critical information in the event of failures or system outages. Regular backups of persistent data can also be performed to minimize data loss and ensure business continuity.
Compliance and Regulations: Certain industries and regulatory frameworks require data to be stored securely and for specific periods. Data persistence allows organizations to comply with these regulations by retaining data for the required durations and implementing appropriate security measures.
Efficient Collaboration and Development: Data persistence facilitates collaboration among developers working on the same application. By persisting data, developers can easily share and access the same datasets, enabling seamless integration and testing of new features and updates.
Advanced Data Analysis: Persistent data can be leveraged for in-depth analysis, reporting, and business intelligence purposes. By retaining historical data, organizations can gain insights, identify patterns, and make data-driven decisions.
To achieve data persistence in containerized environments, various approaches can be adopted, such as using storage plug-ins, data volume containers, or mounting a local directory as a data directory within containers. These techniques enable the separation of data management from containers, ensuring that data remains available and durable even as containers come and go.
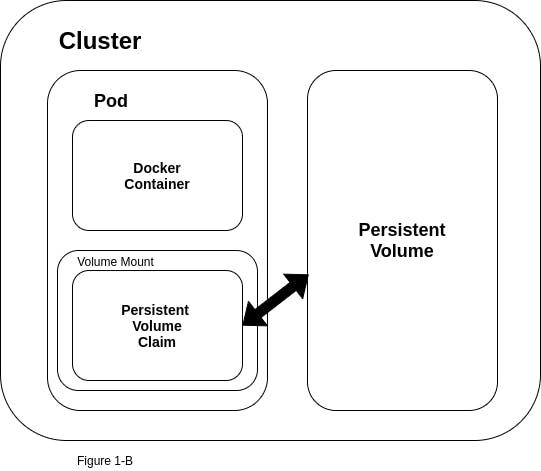
Task 1: Adding a Persistent Volume to your Deployment
Step 1: Creating a Persistent Volume (pv.yml) To begin, let's create the Persistent Volume YAML file (pv.yml). In this example, we will utilize a file on the node as our storage medium. Here's a sample pv.yml file:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-todo-app
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
hostPath:
path: "/tmp/data"
Step 2: Creating a Persistent Volume Claim (pvc.yml) Next, we need to create a Persistent Volume Claim YAML file (pvc.yml) that references the Persistent Volume we just created. Here's an example pvc.yml file:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-todo-app
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 500Mi
Step 3: Updating the deployment configuration (deployment.yml) Now, let's update the existing deployment YAML file (deployment.yml) to include the Persistent Volume Claim. Here's an example of how the modified deployment.yml file might look:
apiVersion: apps/v1
kind: Deployment
metadata:
name: todo-app-deployment
spec:
replicas: 1
selector:
matchLabels:
app: todo-app
template:
metadata:
labels:
app: todo-app
spec:
containers:
- name: todo-app
image: rishikeshops/todo-app
ports:
- containerPort: 8000
volumeMounts:
- name: todo-app-data
mountPath: /app
volumes:
- name: todo-app-data
persistentVolumeClaim:
claimName: pvc-todo-app
Step 4: Applying the changes Now that we have created the necessary PV, PVC, and updated deployment YAML files, it's time to apply the changes. Execute the following command:
kubectl apply -f pv.yml
kubectl apply -f pvc.yml
kubectl apply -f deployment.yml
Step 5: Verification To ensure that the Persistent Volume has been successfully added to your deployment, you can use the following commands:
kubectl get pods
kubectl get pv
Task 2: Accessing data in the Persistent Volume
Step 1: Connecting to a Pod To access the data stored in the Persistent Volume from within a Pod, we need to connect to the Pod. Execute the following command:
kubectl exec -it <pod-name> -- /bin/bash
Step 2: Verifying access to data Once you are inside the Pod, you can verify the accessibility of the data stored in the Persistent Volume. Use standard file system commands to navigate to the appropriate mount path and inspect the data.
Conclusion:
Congratulations! You have successfully added a Persistent Volume to your Kubernetes deployment, providing data persistence and resilience. By following the step-by-step instructions, you have learned how to create a Persistent Volume, configure a Persistent Volume Claim, update your deployment configuration, and verify the integration. Leveraging Persistent Volumes enhances the reliability and scalability of your applications in a Kubernetes environment.
Remember, data persistence is crucial for any production-grade application, and Kubernetes offers robust features to meet those requirements. Stay tuned for more exciting topics on containerization, DevOps, and Kubernetes!

To connect with me - https://www.linkedin.com/in/subhodey/